
How Databricks simplifies complex data stacks
6 Jun 2025

Databricks gets a lot of attention – and for good reason. It’s pitched as the all-in-one platform for data engineering, machine learning, analytics, and AI. That’s a big promise. But in our experience at EdgeRed, it mostly lives up to the hype.
We’ve used Databricks with clients across industries – from supermarket giants and retail platforms to property analytics and insurance providers. If you’re trying to bring your data and AI strategy into one streamlined environment, here’s what we think you should know.
What is Databricks?
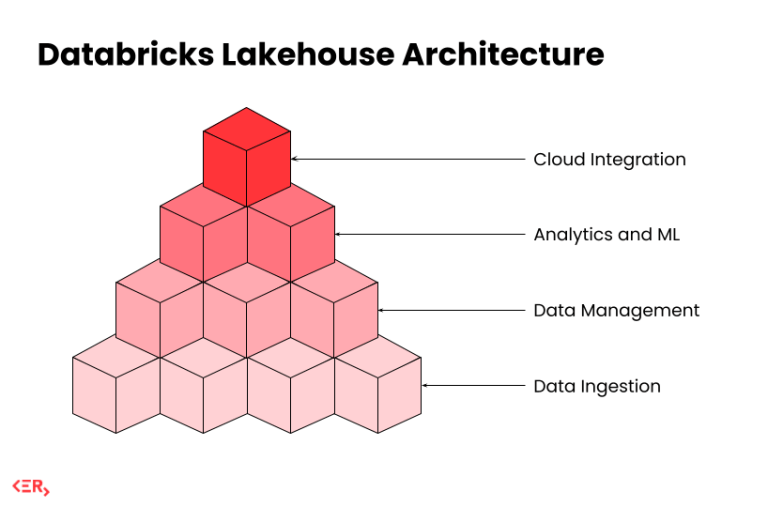
At a high level, Databricks is a cloud-based data platform built around Apache Spark. It’s designed to handle everything from raw data ingestion to analytics and ML – all in one environment.
It’s built on the Lakehouse architecture, which combines the scalability and flexibility of a data lake with the performance and structure of a warehouse. That means you can manage structured and unstructured data, run pipelines and train models, all from one place.
It works across AWS, Azure, and GCP, and it’s especially useful when teams are juggling both analytics and machine learning at scale.
Why we like using it
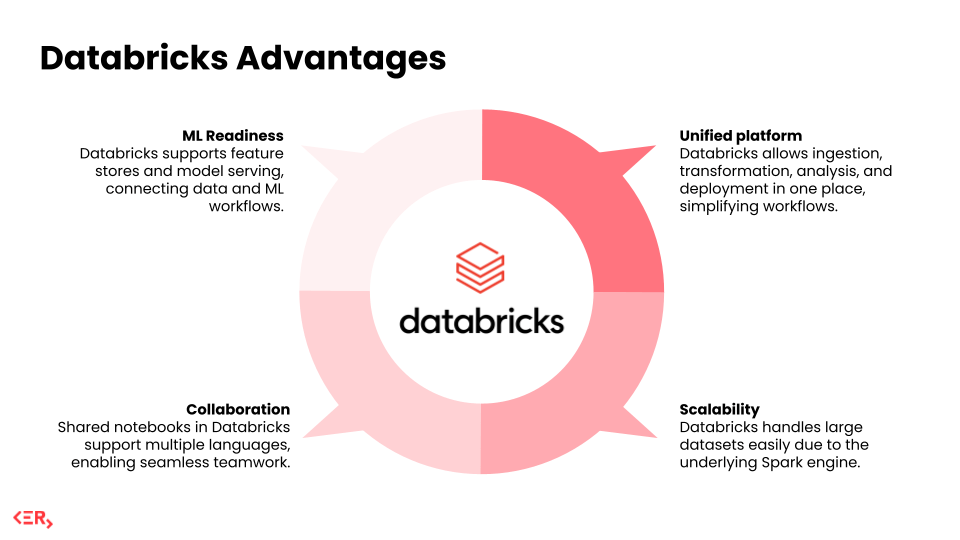
1. One platform to do it all
You can ingest, transform, analyse, and deploy – without jumping across tools or building fragile integrations. We’ve seen this drastically simplify workflows for clients who were previously duct-taping solutions together.
2. Built to handle scale
Whether it’s real-time pricing data in retail or years of claims history in insurance, Databricks can handle heavy lifting with ease. The underlying Spark engine gives it real power without a ton of configuration.
3. Collaboration actually works
Databricks’ shared notebooks support Python, SQL, and Scala – and make collaboration across teams seamless. Engineers, analysts, and data scientists can all work in the same place, without stepping on each other’s toes.
4. Ready for ML (and not just as an add-on)
With built-in support for feature stores, experiment tracking, and model serving, Databricks is one of the few platforms where data and ML workflows truly connect. We’ve used it for use cases like demand forecasting, customer churn models, and risk prediction.
Where it fits in your stack
Databricks is often the glue that holds a modern stack together. Here’s how it typically fits:
- Data lands in cloud storage via Fivetran, Airbyte, or APIs
- Databricks handles ingestion, transformation, and advanced modelling
- Results are served through dashboards or fed into apps via APIs
- ML models are trained, tracked, and deployed – all within the same platform
It’s especially powerful when you need flexibility and scalability without sacrificing control.
What to watch out for
Databricks is powerful, but like any tool, there’s a right way to use it. Some advice we give early:
- Be smart with clusters – poor config can lead to unnecessary cost blowouts
- Set up your architecture properly – especially around data access and governance
- Not just for data scientists – it’s a full-stack platform, but it works best with cross-functional input
“Treat your notebooks like code — modularise logic, use version control, and always parameterise paths and environments” – Molly, Senior Data Engineer @EdgeRed
We’ve got certified Databricks engineers on the team, and we’ve seen first-hand how the platform performs across industries with very different needs.
When we recommend it
Databricks makes sense when:
- You’re working with large, complex datasets
- You’re building ML models and need proper orchestration
- You’ve got scattered tools that aren’t scaling well
- You’re on cloud infrastructure and want a unified approach
If you’re managing pipelines across three or four platforms and struggling to get models into production, Databricks is probably worth a closer look.
Final thoughts
Databricks brings serious firepower to the modern data stack. It’s not the simplest platform – but if your data team is ready for scale, automation, and ML integration, it delivers.
At EdgeRed, we’ve helped clients across retail, insurance, property, and more get the most out of Databricks. Whether it’s a greenfield setup or rescuing a project mid-flight, we know where the value lives – and how to get to it faster.
Want to see if it’s the right fit for your team? Let’s chat. Our Databricks-certified engineers are happy to share what’s worked (and what hasn’t) from real-world projects.
EdgeRed is a registered Databricks Partner, you’ll find us at their directory too.
This blog was written by Molly, assisted by E.R.I.C.A.
About EdgeRed
EdgeRed is an Australian boutique consultancy with expert data analytics and AI consultants in Sydney and Melbourne. We help businesses turn data into insights, driving faster and smarter decisions. Our team specialises in the modern data stack, using tools like Snowflake, dbt, Databricks, and Power BI to deliver scalable, seamless solutions. Whether you need augmented resources or full-scale execution, we’re here to support your team and unlock real business value.
Subscribe to our newsletter to receive our latest data analysis and reports directly to your inbox.



