
Anonymising Data for AI Agents: Using the Latest Tools Without Risking Privacy
18 Jul 2025

As AI agents become more integrated into day-to-day operations—from answering customer queries to summarising internal reports—companies face a fundamental challenge: how do we safely share sensitive data with AI models?
Whether you’re experimenting with OpenAI’s GPT models, Google Gemini, or building your own AI assistants, data privacy is a show-stopper. And for good reason.
The Problem: AI Is Powerful—But Data Privacy Is Non-Negotiable
Let’s say you want to send data to an AI agent to summarise a client email or generate insights from customer records. Chances are, that data includes personally identifiable information (PII)—names, phone numbers, addresses, even Medicare numbers in Australia’s case. You have a few options, none of them ideal:
- Manually censor the data before it goes to the model. It’s time-consuming and prone to human error.
- Use an enterprise AI solution (like ChatGPT or Gemini Enterprise) and trust their privacy guarantees.
- Deploy an existing model in a secure environment—run a pre-trained AI model on-prem, air-gapped, or behind firewalls.
Across the board, teams are forced to choose between AI capabilities and privacy confidence.
But what if there was a middle ground?
Smarter Solutions: Techniques for Anonymising Data Before It Hits the Model
We’ve been working on modular approaches to pre-process and anonymise data—without losing context or functionality—before it goes into an AI system. Here’s how it can work:
🔐 1. Tokenising SQL with Encryption
For structured queries, we use SQL tokenisers to encrypt queries before they go to the AI. This lets the model help optimise or correct the query without ever seeing sensitive table names or column values. After processing, the query can be decrypted and executed safely.
A look under the hood
Our approach works by first using specialised open sourced libraries like sqlparse to break the query down into its fundamental components, or “tokens.” We examine the type of each token.
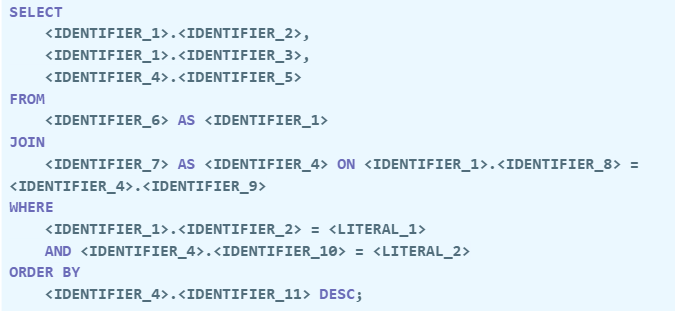
If a token is a core SQL command (like SELECT, FROM, WHERE), an operator (=, >), or punctuation, it’s left as is. However, if the token is a potentially sensitive identifier (a table name, column name, or alias) or a literal value (like ‘Payment Pending’ or 0), it’s swapped out for a generic placeholder (e.g., <IDENTIFIER_1>, <LITERAL_1>).
This creates a structural template of the original query while storing all the original values in a separate “de-anonymisation map,” ensuring the AI can process the query’s logic without accessing any sensitive data.
A Fun Example (The Ice Cream Incident!)
Imagine you work at a hospital where a patient, Sherman Cone, has just been admitted after eating three entire tubs of “Triple Chocolate Fudge” ice cream. To review his case, you need to query the hospital’s patient database. Sending a raw SQL query containing his details to an AI for help with analysis would expose confidential patient data.
To prevent this, our solution automatically redacts the query. It replaces every sensitive detail (table names, column names, and specific values) with generic placeholders. This process generates two outputs: a safe, anonymized query to send to the AI, and a private “map” that allows us to restore the original details from the AI’s response.
Original Query (Before Redaction)
This is a sensitive query containing Sherman’s protected health information that should not be shared with an external service.

Redacted Query (Safe for the AI)
The AI only sees this version, which contains no sensitive information but preserves the query’s structure.
De-anonymization Map (Kept Private)
This map can be kept on your local machine to add the correct context to the AI’s response

👁️🗨️ 2. Removing PII with Microsoft Presidio
Presidio is a powerful open-source tool from Microsoft that automatically detects and redacts sensitive data like names, emails, and credit cards. We extend it with Australia-specific recognisers—like Medicare numbers or TFNs—to suit local data privacy needs.
“Presidio gave us the control and transparency we needed. It lets us build a privacy-first pipeline that automatically detects and redacts sensitive data right down to Australia specific identifiers like Medicare and TFNs, before anything reaches the AI model. It’s become a core layer of our AI architecture.” – Rony Morales, Data Consultant at EdgeRed
Presidio works by combining several proven text analysis methods into a single framework. It leverages Natural Language Processing (NLP) to understand context and identify entities like names or locations, while also using regular expressions (regex) to find pattern-based data like email addresses or phone numbers. To ensure high accuracy, it can also employ other techniques like checksum validation for credit card numbers, creating a powerful, layered system for detecting a wide range of PII.
A Fun Example (A follow up to Sherman)
Now that you’ve reviewed the case, the hospital’s patient care team wants to send a follow-up email to Sherman. Imagine you ask an AI to help draft a template. Your initial prompt to the AI might include his sensitive details to give the AI context about the specific ice cream incident
The Original Prompt (Unsafe for AI)
Without protection, all of Sherman Cone’s Personally Identifiable Information (PII) could be sent directly to the AI model.

The Censored Prompt (Safe for AI)
Using Presidio, we automatically redact the sensitive data before it ever leaves your system. The AI only sees this safe, anonymized version, which preserves the context needed to complete the task without exposing any PII.

What Presidio Recognized
Here is a look at exactly what our script identified in the original text. The conflict resolution logic correctly prioritized the more specific AU_MEDICARE_NUMBER and PHONE_NUMBER entities over the more generic DATE_TIME recogniser

🧠 3. Using a Local LLM to Censor External Prompts
Before your prompt hits an external LLM like ChatGPT, we can run it through a local lightweight model trained to identify and remove PII. Bonus: it can even report back what it censored, helping teams validate what’s being redacted.
These techniques aren’t mutually exclusive—they can be chained together, layered, or selectively applied depending on the data, the task, and the AI model being used.
What It Could Look Like: An Internal Privacy Gateway for AI
Imagine an internal chatbot that connects to the latest external LLMs—but with a privacy gateway running in the background:
- You type your query, including sensitive customer data.
- It passes through a local pipeline that:
- Detects and redacts PII
- Tokenises SQL statements
- Logs what was censored (optionally)
- The anonymised version is sent to the AI agent.
- When results come back, the system de-anonymises the output using the stored mappings.
You get the power of cutting-edge AI, without exposing sensitive data. Think of it like having a secure translator between your data and the model.
The Goal: Use AI Without Compromising on Privacy
Ultimately, this approach helps companies unlock the value of AI tools while maintaining data sovereignty and trust.
- No need to manually scrub data
- No need to hand over raw info to third parties
- No need to fall behind on the latest AI capabilities
Just put in data, let the system strip out what’s sensitive, and get clean, private results—with the option to reverse it on your side when needed.
Frequently Asked Questions (FAQs)
1. Why is anonymising data important when using AI models?
Anonymising data protects sensitive information—like names, emails, or Medicare numbers—from being exposed to third-party AI models. It helps organisations stay compliant with data privacy laws while safely leveraging AI tools like ChatGPT or Gemini.
2. What techniques are used to anonymise data before sending it to AI?
Common techniques include tokenising SQL queries, using PII redaction tools like Microsoft Presidio, and running prompts through local language models to detect and remove sensitive information before data reaches the AI.
3. Can I use AI tools without compromising data privacy?
Yes. By setting up a privacy gateway that anonymises, redacts, and logs sensitive data before interacting with AI agents, businesses can safely use AI without exposing confidential client or operational data.
4. What tools can help with AI data anonymisation in Australia?
Tools like Microsoft Presidio (extended with AU-specific recognisers), local LLMs, and SQL tokenisers are effective for anonymising Medicare numbers, TFNs, and other Australian PII before using AI models.
This blog was written by Tim, with assistance from E.R.I.C.A.
About EdgeRed
EdgeRed is an Australian boutique consultancy with expert data analytics and AI consultants in Sydney and Melbourne. We help businesses turn data into insights, driving faster and smarter decisions. Our team specialises in the modern data stack, using tools like Snowflake, dbt, Databricks, and Power BI to deliver scalable, seamless solutions. Whether you need augmented resources or full-scale execution, we’re here to support your team and unlock real business value.
Subscribe to our newsletter to receive our latest data analysis and reports directly to your inbox.



